
This is an old video I made in 2018 – feels more relevant than ever. Apologies for the creepy voice:
Update: This is one of many text-to-video tests I’ve been doing.
Avatar is super impressive – but it’s missing a lot of the unique perspectives in the source material I provided…
Austrian economics is a school of economic thought that focuses on the individual and their actions as the driving force behind economic behavior. This approach stands in contrast to other schools of economic thought, such as Keynesian economics, which focus on the aggregate behavior of the economy.
One key concept in Austrian economics is the idea of subjective value. This means that the value of a good or service is determined by the individual and their subjective preferences, rather than being determined by objective measures such as cost or market demand. This concept is at the heart of the Austrian approach to economics, and it has implications for management as well.
In terms of management, the Austrian approach emphasizes the importance of individual incentives and the role they play in decision making. For example, a manager who understands the concept of subjective value may be more likely to offer employees incentives that are tailored to their individual preferences, rather than using a one-size-fits-all approach. This can lead to more motivated and engaged employees, who are more likely to be productive and contribute to the overall success of the organization.
Another key concept in Austrian economics is the idea of entrepreneurship. This refers to the process of taking risks and making decisions in order to create value in the economy. Entrepreneurs are seen as the driving force behind innovation and economic growth, and they are crucial to the Austrian understanding of how the economy works.
In terms of management, the emphasis on entrepreneurship means that managers should be encouraged to take risks and make bold decisions in order to drive innovation and growth within their organizations. This approach can lead to a more dynamic and adaptable organization, which is better equipped to respond to changes in the market and to seize opportunities as they arise.
Overall, the Austrian approach to economics and management emphasizes the importance of individual incentives and entrepreneurship, and it offers a unique perspective on how the economy and organizations operate. By understanding and applying these concepts, managers can be better equipped to make decisions that drive innovation, growth, and success within their organizations.
I’d forgotten about these posters originally from 1999 until I just overhead somebody say “The Document is Not the Process”.
There are:
- The Document is Not The Project
- Plan with Models, Manage with Markets (repeat)
- I’m sorry, is my work interfering with your management (again)?
- It’s easier to manage 10 people than it is to be managed by 10 people
- Management is the process of deciding which decisions don’t need to be made by consensus
- The 7 Steps to Successful IT Transformation

“Is it time to retire the title of manager?”
https://www.strategy-business.com/blog/Is-it-time-to-retire-the-title-of-manager?gko=e5846
I think one aid to thinking is physical representations of concepts. This adds understanding and collaboration.
I’m not unique in this view though the first example of somebody who shared this view that comes to mind is L. Ron Hubbard of Scientology fame. Make of that what you will.
As part of my work with Aware Services I’ve made some boardgames pieces that represent the foundations of some of the work we do. See the video below:
See also:
In that perverse type of functional organisation that has a functional business unit for each profession, there is a predictable progression for each function.
- The function cannot succeed until it is centralised
- The function cannot succeed until it has the sponsorship of the CEO
- The function cannot succeed until it has its own “Chief xxxx Officer”
- The function cannot succeed until everybody understands that the function is “everybody’s responsibility”
- The function cannot succeed until it has the resources to engage with “everybody”
- The function cannot succeed until there is a dedicated business unit that makes the function part of the business-as-usual process
- The function cannot succeed until it has input into the strategy of the organisation
- The function cannot succeed until it is part of the organisation’s culture
- The function cannot succeed until it reports to me
I find it amusing that Digital folks can simultaneously pronounce that digital is a complete change in mindset that impacts the entire organisation, while also being upset when people outside the digital department start doing digital without them.
“They are doing it wrong! They don’t get it!”
Maybe. But maybe not.
You can’t use dramatic socio-technical trends to justify your approach but then claim that nobody else is evolving. Where do you think trends come from? Or where they are directed.
“Oh this is just the inevitability digital backlash. We predicted that.”
Yes, didn’t we all.
Once everybody “gets” digital who will we say doesn’t get it? Maybe the ageing digital folks?
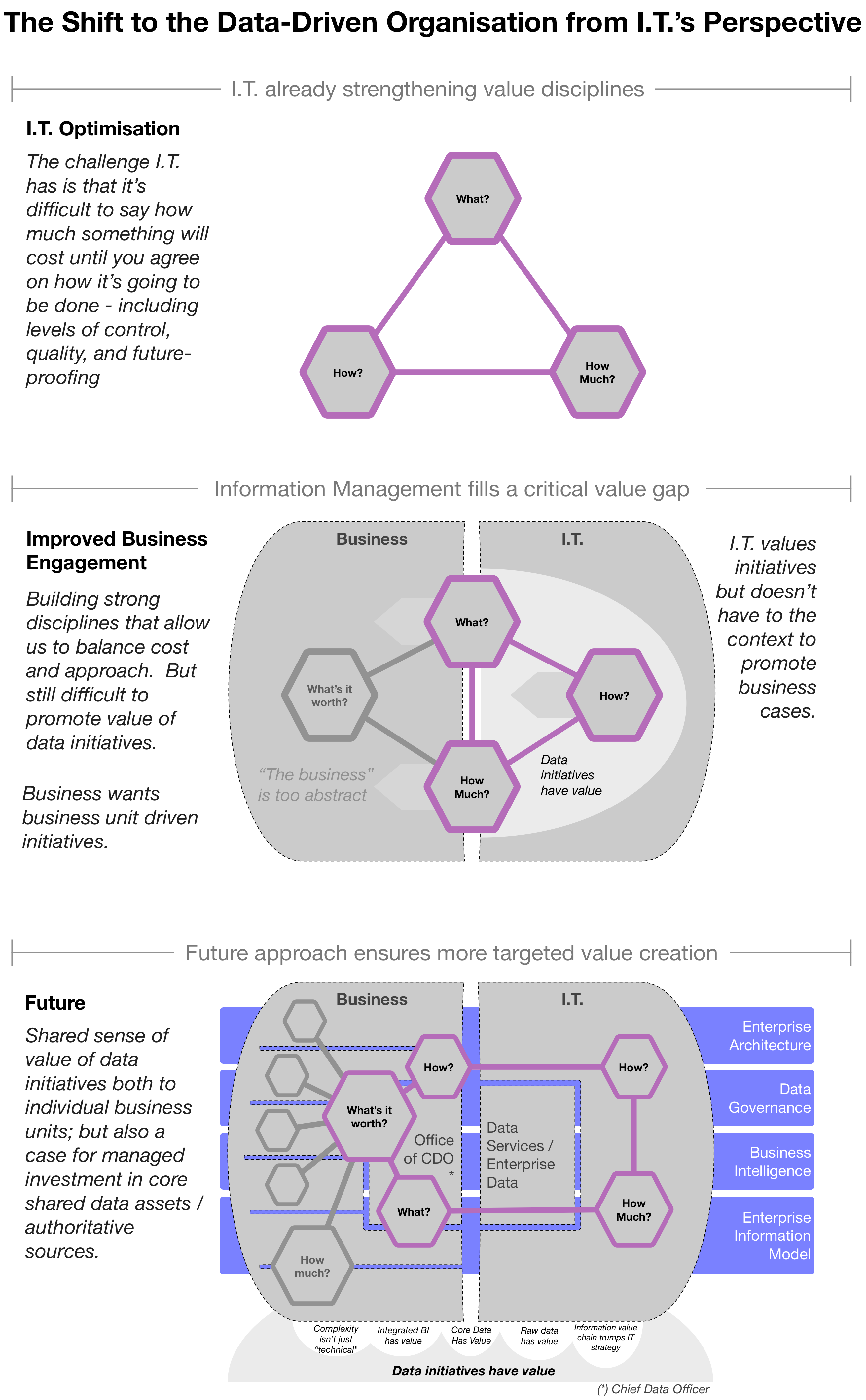
I.T. gets a bad wrap in some information management initiatives. I prefer to take the approach that many IT disciplines are helpful for better information management. The shift from I.T.’s perspective often looks like this:
Good capability-based planning article: http://fia.workem.org/index.php?option=com_content&view=category&layout=blog&id=14&Itemid=111